
CPU的分支预测模型
记录水群中学到的一个CPU机制
目录
例子
| |
在这个例子中,第18行的 Arrays.sort()决定了数组是否是有序的,结果上可发现排序后的数组执行效率更高。
引子
想象一个洗车的完整场景:分为洗车和擦洗两个步骤,前车驾驶到擦洗地段时,后车就可以先开始洗车了。 CPU的流水线机制就是大抵如此。使CPU能够使指令能够不必完全执行完毕就开始执行下一个指令,故而提高了系统吞吐量。
然而,流水线也有一些局限性:
- 不同阶段之间的时钟周期不同,需要适配最慢阶段
- 流水线过深虽然并行越多,但是寄存器也越多,增加访问次数可能会增加延迟
- 不同阶段之间可能有相互冲突的访问或者跳转,引入缓冲槽也可能会造成延迟。
虽然如此,流水线还是极大提升了指令执行效率。只是如果碰到的是条件跳转指令,只有每次执行的时候才能判断本次是否跳转,而这个判断就是需要CPU做出“停顿”的。为了解决这个问题,分支预测技术应运而生。
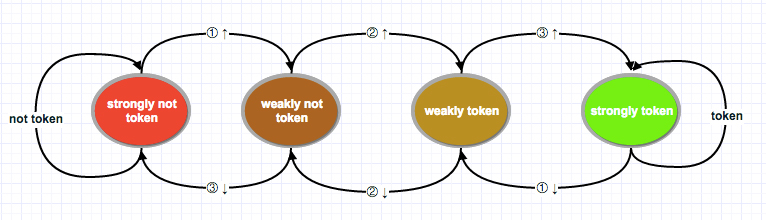
分支预测
分支预测技术会让CPU直接让预测指令进入流水线。当跳转指令执行完成之后,如果预测失败需要清空整个流水线,并重新加载正确分支。其中分支预测技术主要包括:静态、动态、协同
实现过程如同其名,静态预测就是直接选择,而动态预测则是通过指令执行的历史信息进行预测。协同预测需要关联多个跳转指令。
一个相关且更实际的东西是:虚函数调用。虚函数的特点是间接调用、跳转地址不定,且无法在编译期做内联优化。显而易见虚函数很容易导致分支预测失败,频繁清空流水线并重新加载分支从而极大的影响性能。Java虽然没有直接的虚函数调用,但为了实现多态,实际上也是利用虚函数进行的。
优化角度
因为虚函数这种会导致条件转移不确定很容易导致分支预测技术的失败,所以编码层面上也许需要更多的注意去提升执行效果。