PostgreSQL数据库并发控制
写在前面
本文档所有内容基于PostgreSQL 10.23文档整理 https://www.postgresql.org/files/documentation/pdf/10/postgresql-10-A4.pdf 可用以下SQL查询当前PGSQL的隔离级别
| |
在后文中,用PG指代PostgreSQL数据库
事务 Transaction
什么是事务
对于数据库的一系列操作,是这一系列操作的整体的描述。
对于PG来说,单个语句默认就是一个事务
ACID性质
- 原子性 —— 事务最终只有两种结果,执行成功写入数据库/执行失败什么都不影响
事务最容易满足的性质,也是实际开发中最大的特点。事务执行过程中,并不是其他操作不能执行,而是其他事务对该事务的中间状态不可见。
通常通过版本控制/日志实现
- 一致性 —— 事务应当产生合理的结果,如转账例子。
一致性可以说是事务最终的目的
- 隔离性 —— 事务之间应当不产生执行效果上的影响,如事务A执行不应影响事务B执行
实际并发应用中为了保证效率而牺牲的选项
- 持久性 —— 事务一旦提交,就可以保证记录被写入/记录可以被完整恢复。
事务第二容易满足的性质,通过日志实现,保证在事务结束之前存储相关变化
事务的作用
通常的数据库实现来说,对于一连串的SQL语句来说,是否使用事务的直接影响只有一个
- 使用事务会造成这一连串的SQL语句只有成功或者失败——原子性
具体的事务对于数据库的视图问题取决于隔离的级别。
保存点 —— savepoints in PostgreSQL
在PG中,针对一个事务提供了savepoint方案——当一个事务回滚时,可以选择Roll back to savepoint。如此会回滚到最近的一个保存点并提交该点之前所做的所有更改。可以实现类似嵌套事务的逻辑。
锁 locks
Pg中每个语句会自动获取需要的锁来保证隔离性,通常允许同一事务持有冲突的锁,并在回滚或完成事务后释放锁。
可以通过执行sql语句LOCK来显式获取锁/PG执行语句也会自动获取所需要的锁,也可以通过pg_locks查询系统中现有并发持有的锁。
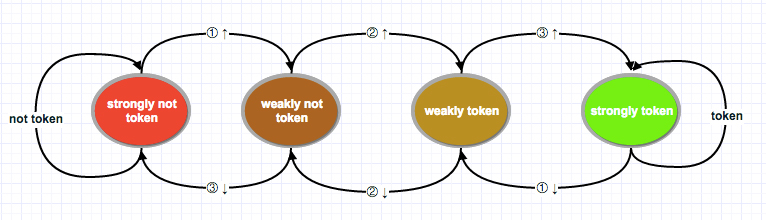
表级锁 —— Table-level Lock Modes
表级锁之间的唯一区别是冲突的对象不同,不同的锁会被不同的语句获得,所以自然形成的语义描述了这个锁
- ACCESS SHARE锁 (访问共享)
只读语句会获取,比如SELECT
只与ACCESS EXCLUSIVE冲突
- ROW SHARE锁(行共享,用来表示表即将写入但表也许还支持修改等)
FOR UPDATE/SHARE会获取,另外多表查询时,只有被select的表才会获取这个锁
与EXCLUSIVE、ACCESS EXCLUSIVE冲突
- ROW EXCLUSIVE(行独占,但是表级锁,类似于意向锁的作用)
UPDATE/DELETE/INSERT(修改表内容的操作)会在影响的表上施加该锁——where等其他引用的表依然是ACCESS SHARE锁
与SHARE、SHARE ROW EXCLUSIVE、EXCLUSIVE、ACCESS EXCLUSIVE冲突
- SHARE UPDATE EXCLUSIVE(表级共享 但可行级更新)
用于保护一个表避免VACCUM和schema变化影响。VACCUM,Create Index Concurrently等DDL获取
与 SHARE UPDATE EXCLUSIVE\SHARE\SHARE ROW EXCLUSIVE\EXCLUSIVE\ACCESS EXCLUSIVE冲突(与自身冲突)
- SHARE(表级共享)
保护一个表避免数据变化。Create Index获取
与ROW EXCLUSIVE, SHARE UPDATE EXCLUSIVE, SHARE ROW EXCLUSIVE, EXCLUSIVE, ACCESS EXCLUSIVE冲突(不与自身冲突但多了ROW EXCLUSIVE)
- SHARE ROW EXCLUSIVE(表级共享且行冲突)
避免表变化且自身冲突。触发器 排序规则等DDL获取
与ROW EXCLUSIVE, SHARE UPDATE EXCLUSIVE, SHARE, SHARE ROW EXCLUSIVE, EXCLUSIVE, ACCESS EXCLUSIVE冲突
- EXCLUSIVE(独占,但允许访问)
并发更新视图时获取
与ROW SHARE, ROW EXCLUSIVE, SHARE UPDATE EXCLUSIVE, SHARE, SHARE ROW EXCLUSIVE, EXCLUSIVE, ACCESS EXCLUSIVE冲突,只允许ACCESS SHARE
- ACCESS EXCLUSIVE(独占且不允许访问)
DROP TABLE, TRUNCATE, REINDEX, CLUSTER, VACUUM FULL, and REFRESH MATERIALIZED VIEW (without CONCURRENTLY) 会获取,即 重型DDL
和所有锁冲突
表级锁冲突示表
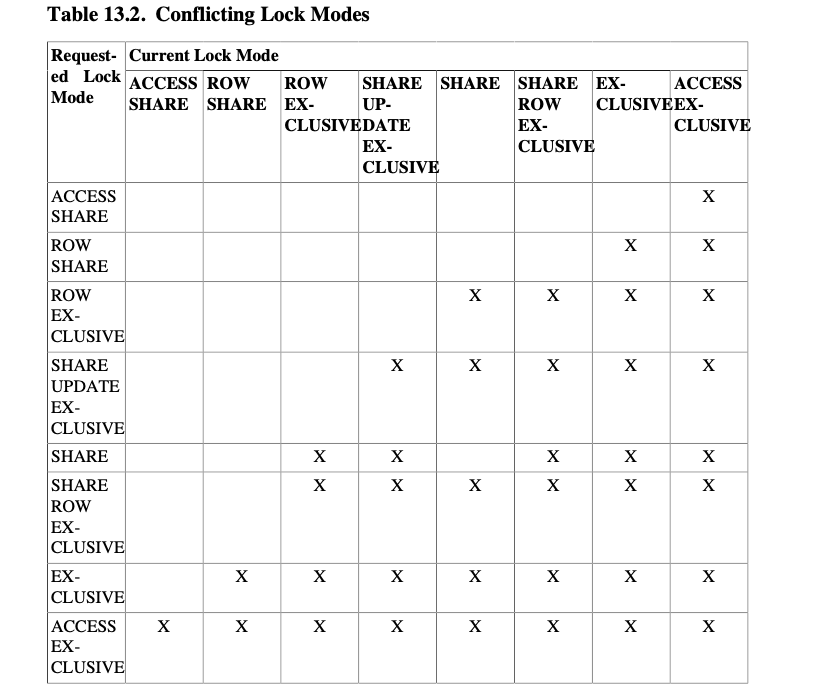
行级锁——Row-level Locks
行级锁只阻止对于行的写入/加锁,在事务结束后释放
- FOR UPDATE
SELECT FOR UPDATE/DELETE单行/UPDATE能作为唯一外键的确定的列(完整性约束) 会获取
虽然获取的时候会停等,但是在RR以上的隔离级别中会报错
- FOR NO KEY UPDATE
不需要FOR UPDATE的SELECT会获取
不会阻塞SELECT FOR KEY SHARE
- FOR SHARE
锁的行是共享行而不是独占,阻塞UPDATE/DELETE/SELECT FOR UPDATE/SELECT FOR NO KEY UPDATE
允许FOR SHARE/FOR KEY SHARE
- FOR KEY SHARE
比SHARE 更弱,允许FOR NO KEY UPDATE,只阻止修改KEY的操作(DELETE、UPDATE)
使用行级锁可能会导致磁盘写入,PG并不在内存中记录被修改的行的信息
行级锁冲突示表
页级锁 —— Page-level Locks
页是PG物理存储管理的基本单位,也就是磁盘里的文件,页级锁在缓存中是有使用的并且每次行的修改都会立即释放。在应用开发级是被屏蔽的
(底层实现无需关心,文档中也并未进一步提及,具体学习也许需要去公开博客或者研读源码)
死锁 —— DeadLocks
死锁的经典场景如两事务持有对方需要的锁,且锁不可剥夺,持续等待和请求。
显示使用锁毫无疑问会增加死锁的可能性,但PG也有内置的死锁解决策略。PG自动探测死锁的可能性,并且通过暂停一个事务并让另一个事务优先处理来解决死锁,即 破坏锁不可剥夺的条件。需要注意的是哪一个事务被选择最终执行是不可预测和依赖的。
解决死锁最好的办法是应用程序通过统一、一致的顺序获取锁(因为PG对语句自动加锁,所以也需要尽可能的一致的顺序获取锁),并且尽量先获取权限大(冲突更严重)的锁。但是由于业务需要,这个是比较难控制的一个问题。即使PG有检测死锁并解决冲突的能力,但也有性能损耗。在慢查询等情况下可以考虑此情形。
若有事务因死锁被暂停(aborted),通过重试来保证逻辑一致性.因为锁直到事务结束才释放,所以足够长的事务毫无疑问会带来更多的锁冲突以及性能损耗。
同时请注意PG有max_locks_per_transaction限制

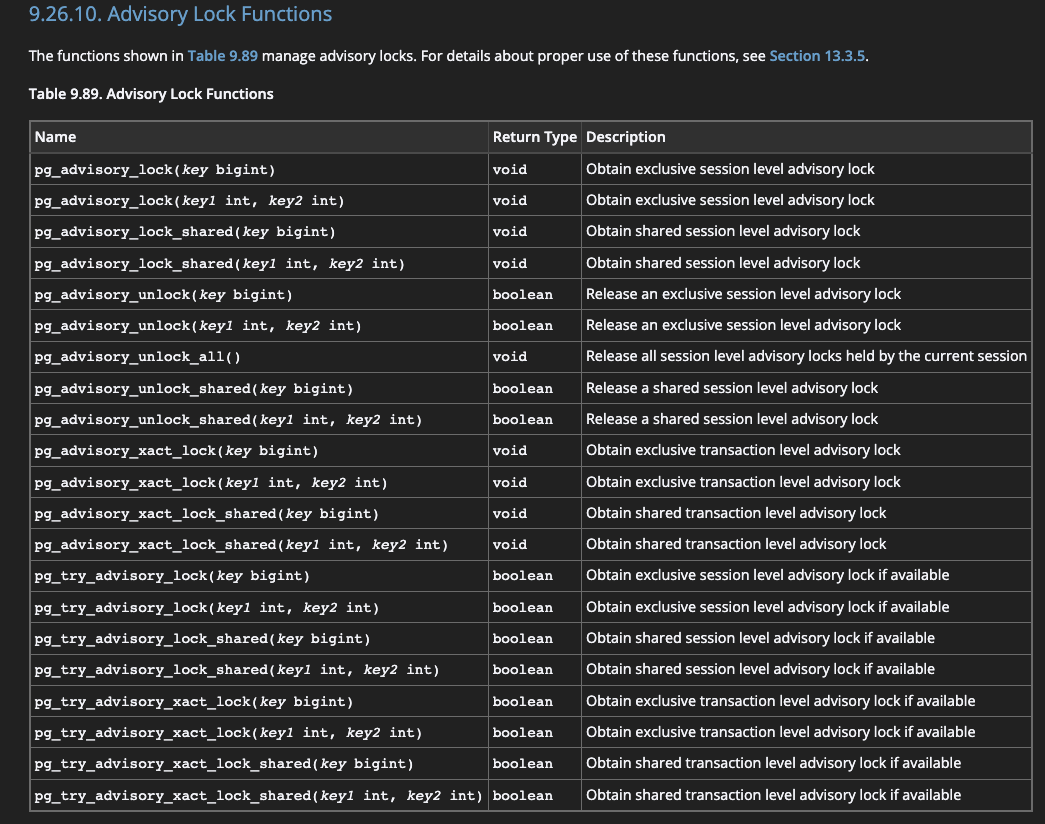
咨询锁 —— Advisory Locks
PG提供的应用程序可以自定义用途的锁。
分为两种级别:Session级别与Transaction级别,即会话TCP连接一直持有的和单个事务中持有的。其除了生命周期不同其余都是一样的互斥效果。Transaction级别与regular锁(也就是表级锁行级锁那些常规的锁)几乎是一样的,即事务开始时获取直到事务结束(commit/rollback) 持有一个咨询锁后,无论级别,都能直接获取一个同名的另一个级别的咨询锁。因为PG一贯支持重入。
咨询锁函数一览表
一种从数据库中查询数据并加咨询锁的方式如下
| |
请注意咨询锁对于排序、LIMIT操作并没有定义的happens-before关系,即可能虽然LIMIT返回10条数据,但是可能对LIMIT前的结果全部获取了咨询锁。
MVCC —— Multiversion Concurrentcy Control 多版本并发控制
对于PG来说,最主要的隔离手段就是通过MVCC和锁的方法.PG最重要的一点是,单纯的SELECT永远不会被修改表的语句阻塞,即使在最高的隔离级别里。
PG中MVCC的实现里,每一个事务或操作中都被标记一个XID。每当一个这样的主体开始操作,PG通过自增的方式返回一个XID赋值其上。而每一行数据都有自己的版本,而这个版本源于每一个操作这一行数据的主体XID。
例如,当XID为x的操作执行一个Insert并成功提交时,PG会在行中插入额外的版本信息——xmin= x。在今后所有的读取操作中,所有小于当前XID的行会被当前操作所读取。也就是说,只有当写入的事务完成后,其修改的行内容只会在其之后开始的事务可见。
DELETE和UPDATE会插入xmax值,当xmax值大于当前事务ID,说明该数据已经被修改/删除了,当xmax小于当前事务id时,则说明该行是有效的。
从抽象的角度来看,MVCC通过版本的额外信息存储来换取并发的性能减少阻塞带来的性能损失。
事务隔离 —— Transaction Isolation
数据库并发读写主要问题有以下四点
- 脏读
事务读取到了其他事务还未提交的数据
- 不可重复读
事务中前后重复读取的同一数据行可能会不一致——事务执行中,有其他并行事务更改了这些数据行
- 幻读
事务中前后执行范围查询可能会有数据行数量上的不同——事务执行中,有其他并行事务插入或删除了符合范围查询条件的数据行。
- 串行化错误
一连串的事务的执行结果和任何执行顺序下的串行化结果都不同
PG提供了SQL标准的四种隔离级别,但是实际上只实现了三种:并没有实现Read Uncommited级别。因此即使PG中设置了隔离级别为Read Uncommited,实际上也依然是默认的Read Commited级别的。
PG事务隔离能力表
![]()
读提交 —— Read Commited Isolation Level
作为PG默认的隔离级别。XID被每个单独语句锁拥有。
在这个级别里,事务中每个语句所看见的数据版本,是 语句执行前的版本,即事务中前后执行的查询语句可能看到的数据版本不一致。这也是可能会出现不可重复读的原因。从效果上来看,SELECT的目标,实际上是整个数据库在执行SELECT之前的一个快照版本。在读提交中,SELECT对其他事务还没提交的修改是不可见的,然而对本事务先前所修改的内容在逻辑上自然是可见的。
对于UPDATE/DELETE/SELECT FOR UPDATE or SHARE语句来说,如果语句检索行时发现其在其他并发事务中被修改或者删除或者锁住,会等待其事务结束再进行操作——如果目标行已经被删除则会直接跳过,并且如果带有WHERE条件筛选时,获取锁之后会再次检查是否匹配条件。当然,SELECT FOR UPDATE这种语句相当于就是选择了修改后的结果。
INSERT ON CONFLICT ON UPDATE(UPSERT)也是类似的,结果会在拿到锁的时候进行判断究竟是update还是insert。
因此,对于并发更新来说,在读提交级别下,更新的语句在被并发修改的行上看到的是最新版本,而未被更新的行是语句执行前的版本。
如下示范了一种比较奇怪的并发错误。
| |
在这里,UPDATE执行的过程中,首先获取了hits=9和10的锁,然后另一个事务中DELETE定位到了hits=10的记录,发现有互斥的行级锁FOR UPDATE,所以会停等,但UPDATE执行结束之后,原来hits=10的记录变为10+1=11,因此不满足WHERE的条件,DELETE就会略过该记录。然而实际上UPDATE更新之后有一行结果hits=9+1=10的记录却没有被DELETE察觉到。这便是所谓的对于自己 并发修改冲突的行上看到的是最新版本,而别的还是执行前的版本的问题所在之一。
在读提交下,即使是单个语句,看到的版本也并不统一。
如果要坚持使用Read Committed隔离级别,请在重要操作上显式使用锁或者外部采取分布式锁等同步手段。
可重复读 —— Repeatable Read Isolation Level
在可重复读下,事务只会看见事务开始前最新的数据版本,这是全表级别的,因此解决了幻读问题。——相比于读提交只能看见语句执行前的版本。XID被每个事务持有。
当然同读提交的一些问题一致,在并发修改冲突时,也会看见更新的版本。如果并发修改时持有锁的一方失败执行事务,会回滚取消数据修改,等待锁的一方就会继续完成目标数据行的修改。不过在可重复读下当发现了数据版本不一致,即并发冲突修改中持有锁的一方成功完成了事务,等待锁的一方自然会发现数据版本发生了变化,此时,等待锁的一方会报错回滚——因此使用该隔离级别时,应用程序务必要写好重试失败的事务的逻辑。
为什么要报错回滚?因为隔离级别要求这个级别下的事务的视图是一致的,不一致就需要回滚重试。
实际上,可重复读也依然会出现不可串行化的结果。经典例子如控制表+目标表的并发读写例子
| |
假设事务A首先插入Batch的信息,然后再往details里批量插入对应的信息。事务B同时查询两个表。事务B在details批量插入前开始,所以在锁冲突行上,事务B看到的数据版本是包括事务A插入的Batch的信息的。
然而因为事务A插入details的时间晚于B开始,所以B看不见details表里的插入内容的版本, 因而等待锁时就不会在details表等待details锁释放。 由此,事务A发现了batch表中存在batch信息,但查不到对应的details信息,导致了数据库信息不一致的问题。
实际上,可重复读是使用Snapshot Isolation实现的,所以相比于使用传统互斥锁的数据库来说,获得高并发能力的PG也确实会牺牲一部分的一致性。
可串行化 —— Serialization Isolation Level
PG所提供的最严格的并发事务隔离级别。该级别下将所有提交的事务 模拟为串行化的提交 ,并且与可重复读一样,需要应用程序必须要考虑支持重试。
实际上,可串行化在实现上,比可重复读仅仅多了一个监控功能。可串行化监控所有可能会导致无法串行化的错误,不引入任何阻塞情况,而在监控到错误时选择抛出错误来回滚事务。
在这个级别下,事务成功提交之前,所有读取到的信息、所有即将写入的数据修改内容都应当被看作无效。除非那些在事务中读取数据可能会等待的语句——比如因为锁而等待的UPDATE、DELETE、SELECT FOR UPDATE等。也就是说,只有成功的事务所获取的数据是符合逻辑一致性的,可以被应用程序使用。
在读提交与可重复读下,要想保证数据的一致性可能需要通过SELECT FOR UPDATE之类的加锁来进行操作,然而实际上在可串行化下,通过一个不阻塞的,类似于标志位的断言锁(predicate lock)来确定是否写操作何时造成影响。 在可串行化下,可以通过以下操作可以优化其性能
- 尽可能标记事务为只读(READ ONLY)
- 使用数据库连接池,控制数据库连接来减少并发冲突
- 一个事务中尽量除了一致性以外不要增添太多语句
- 控制idle_in_transaction_session_timeout可以自动结束数据库连接
- 减少使用锁,因为可串行化本身提供的隔离级别已经很高
- 减少全表顺序扫描
应用级别的数据一致性检查 —— Data Consistency Checks at the Application Level
Read Commited隔离级别下,即使是同一个事务每个SQL语句执行也不保证是相同的视图——可能相同的SQL语句前后执行看到的数据版本是不一致的。
与此相比,Repeatable Read隔离级别下整个事务的视图都保证是一致的——如果不一致则取消执行回滚。但读写冲突也依然会发生。当一个事务A在执行中修改了表,另一个事务B只能读取到旧版本,也即并未被修改的结果。但如果事务B也写入数据,那么加入存在事务C,则会看起来似乎事务C是最先执行的——因为看到的数据版本是最旧的。这会造成事务时序的混乱。而当出现如此混乱的时候,完整性检查就有可能会出现问题——数据库定义上的的一致性就会被破坏。
如前所述,Serializable 隔离级别下,PG增加了非阻塞的监控。当出现这种事务时序问题时,监控就会回滚其中一个事务破坏循环条件,从而保证完整性检查。
通过锁来确保一致性 —— Enforcing Consistency With Serializable Transactions
确定行的锁,可以通过SELECT FOR SHARE/UPDATE进行事务内的锁定,也可以通过适合的表级锁来进行锁定。
需要注意的是 SELECT FOR UPDATE选中的行如果没有执行UPDATE,会导致被选中的行并不会变化版本号,当其他因获取锁而等待的事务获取到对应锁后,依然会进行操作,而不是跳过(由于版本变化而导致的视图不可见)。
例如当不允许表中有存在的uncommited内容时,可以使用share以上级别的表级锁来保证隔离性。
必须要在执行SQL之前进行锁的获取。否则即使在Repeatable Read下,锁获取的时间晚于查询可能会导致查询的版本早于获得锁时,导致会有更新的版本存在,但不可见。
索引与锁 —— Locking and Indexes
此处探讨的锁,与前面探讨的锁几乎完全没有关系——除了页面锁。是物理存储意义上的读写的锁。
PG中,要注意并不是所有的索引访问形式都支持非阻塞的读写锁。
- B树/GiST/SP-GiST索引
使用短期的页级别的读写锁,并且在每个索引行获取或者插入时就释放。高并发性/无死锁。
- 哈希索引
哈希桶级别的读写锁,当整个桶处理完毕后再释放锁。提供最高的并发性(哈希桶天然并发)但可能死锁(锁持有时间更长)
- GIN索引
类似B树,但GIN索引在每一个索引插入时,会额外插入许多内容,是一个相对较重的操作。
通常来说,处理标量数据使用B树会有更好的并发性能,而对于非标量数据使用GiST或者SP版本的会效果更好。哈希索引更适合没有范围查询、等值查询更多、数据分布更均匀,对时间要求高而内存宽松的情况
写在最后
本文档的初心并不是想做一个八股文文档,一切的设计和实现都需要实际上手去体验尝试才能更多地化为认知和能力。